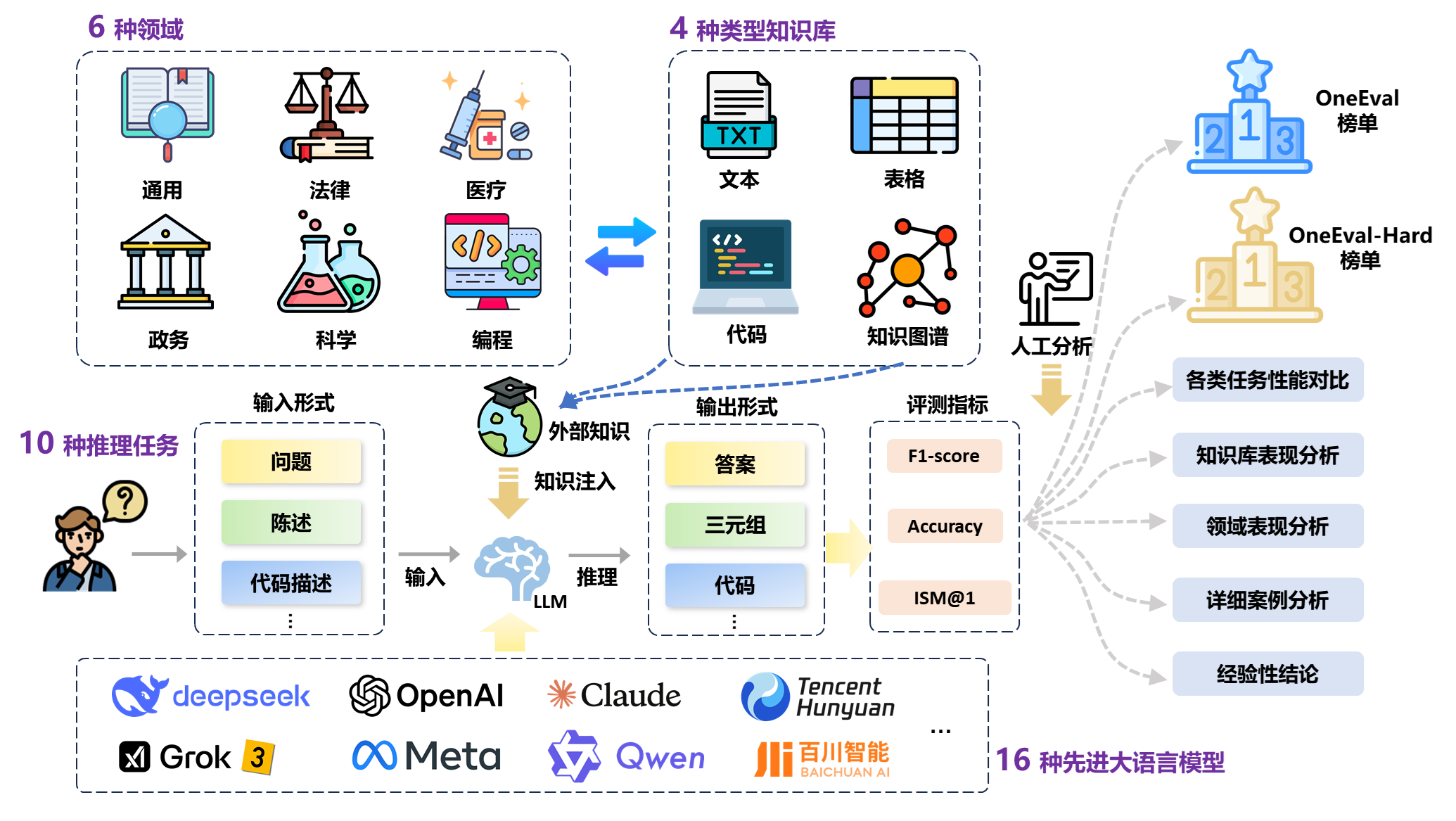

文本知识库
外部知识库涵盖非结构化文献与文档,测试模型在文本型知识的理解,以及复杂语境下的语义建构、信息抽取等能力。

表格知识库
以结构化表格数据为基础,考查模型在结构化知识的理解,以及对数值、分类与层级信息的处理、比较与逻辑计算能力。

知识图谱
基于实体-关系三元组构建的结构化语义网络,评估模型在图结构知识的理解,以及多跳推理、实体对齐与关系识别等任务中的表现。

代码知识库
包含函数文档、源代码与API说明,聚焦模型在程序型知识的理解,以及代码补全、自然语言到代码生成等能力。



外部知识库涵盖非结构化文献与文档,测试模型在文本型知识的理解,以及复杂语境下的语义建构、信息抽取等能力。
以结构化表格数据为基础,考查模型在结构化知识的理解,以及对数值、分类与层级信息的处理、比较与逻辑计算能力。
基于实体-关系三元组构建的结构化语义网络,评估模型在图结构知识的理解,以及多跳推理、实体对齐与关系识别等任务中的表现。
包含函数文档、源代码与API说明,聚焦模型在程序型知识的理解,以及代码补全、自然语言到代码生成等能力。